Along with our Theoretical Research team at Bitdefender, we want to put Romania on the map of top research. I am very involved in building a community by organizing and taking part in regular theoretical seminars, workshops, courses, tutorials, reading groups, summer schools, and academic meetings in Bucharest.
I received my BSc and MSc from the University Politehnica Bucharest, on Compilers and Distributed Systems. I have a strong background in Mathematics and Physics, with awards at national and international contests. More recently (Feb 2022), I defended my PhD at University of Bucharest, with Efficiently Exploiting Space-Time Consensus for Object Segmentation and Tracking in Video thesis, under Marius Leordeanu and Gheorghe Stefanescu supervision. I had outstanding members in the PhD Defense Committee: Tinne Tuytelaars - KU Leuven, João F. Henriques - University of Oxford, Viorica Pătrăucean - Google DeepMind. I am profoundly grateful to you all.
My current research interest is in Generalization problems under Distribution Shifts.
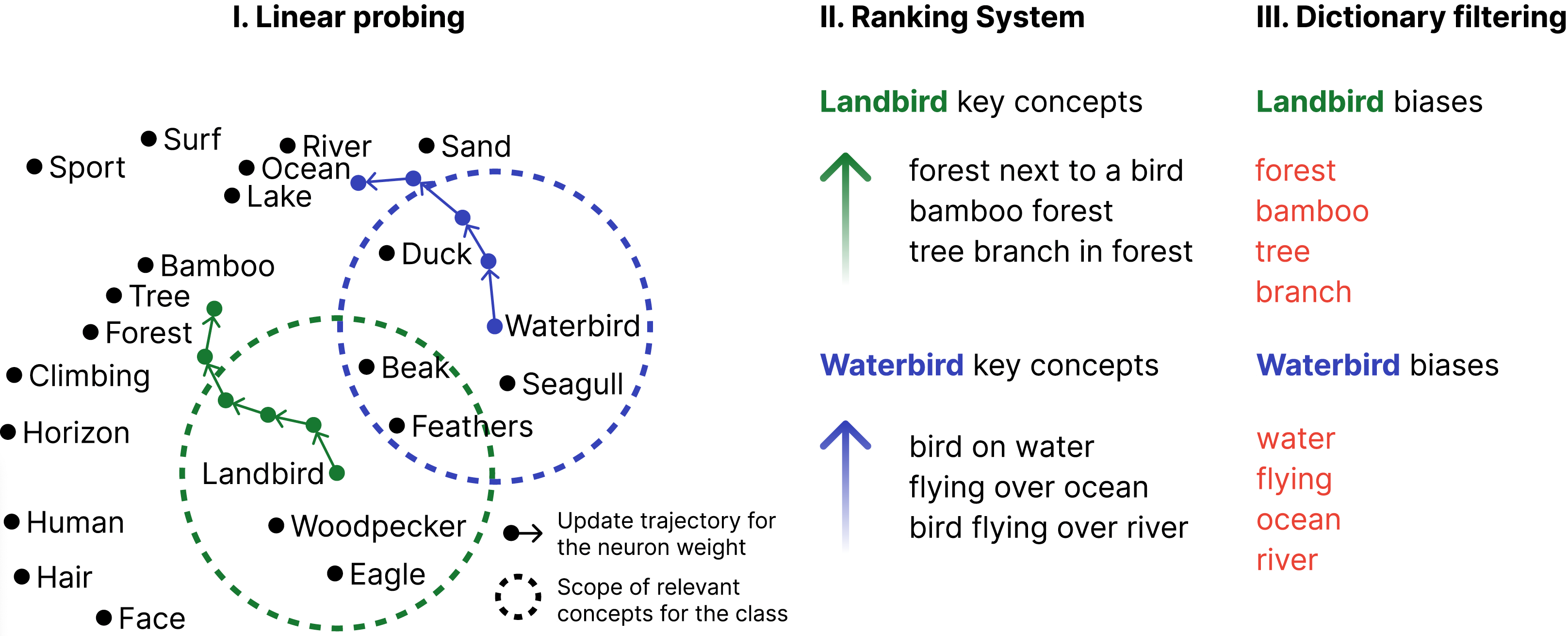
Datasets and pre-trained models come with intrinsic biases. Most methods rely on spotting them by analysing misclassified samples, in a semi-automated human-computer validation. In contrast, we propose ConceptDrift, a method which analyzes the weights of a linear probe, learned on top a foundational model. We capitalize on the weight update trajectory, which starts from the embedding of the textual representation of the class, and proceeds to drift towards embeddings that disclose hidden biases. Different from prior work, with this approach we can pin-point unwanted correlations from a dataset, providing more than just possible explanations for the wrong predictions. We empirically prove the efficacy of our method, by significantly improving zero-shot performance with biased-augmented prompting. Our method is not bounded to a single modality, and we experiment in this work with both image (Waterbirds, CelebA, Nico++) and text datasets (CivilComments).
Paper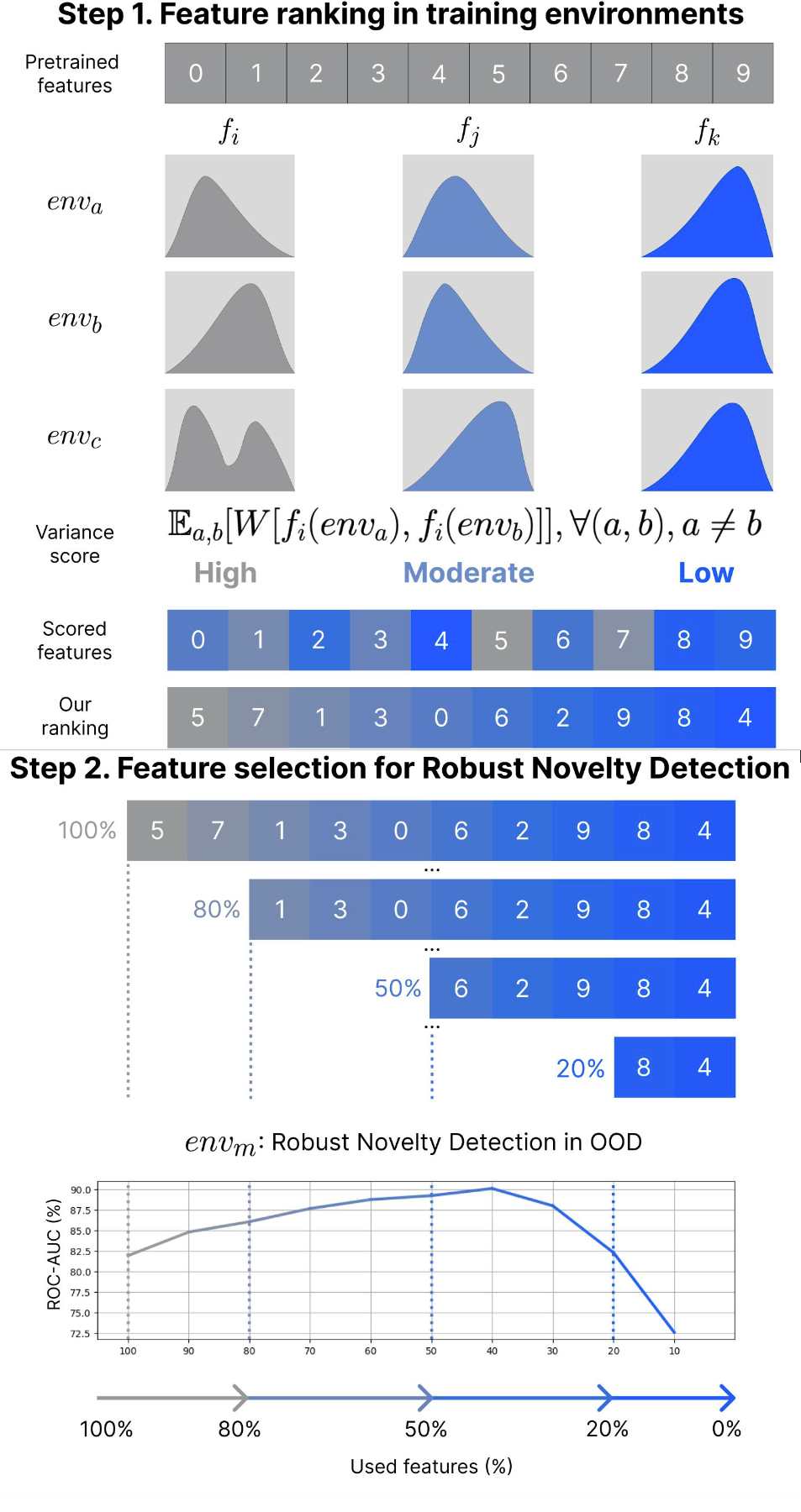
Novelty detection aims at finding samples that differ in some form from the distribution of seen samples. But not all changes are created equal. Data can suffer a multitude of distribution shifts, and we might want to detect only some types of relevant changes. Similar to works in out-of-distribution generalization, we propose to use the formalization of separating into semantic or content changes, that are relevant to our task, and style changes, that are irrelevant. Within this formalization, we define the robust novelty detection as the task of finding semantic changes while being robust to style distributional shifts. Leveraging pretrained, large-scale model representations, we introduce Stylist, a novel method that focuses on dropping environment-biased features. First, we compute a per-feature score based on the feature distribution distances between environments. Next, we show that our selection manages to remove features responsible for spurious correlations and improve novelty detection performance. For evaluation, we adapt domain generalization datasets to our task and analyze the methods behaviors. We additionally built a large synthetic dataset where we have control over the spurious correlations degree. We prove that our selection mechanism improves novelty detection algorithms across multiple datasets, containing both stylistic and content shifts.
Code Paper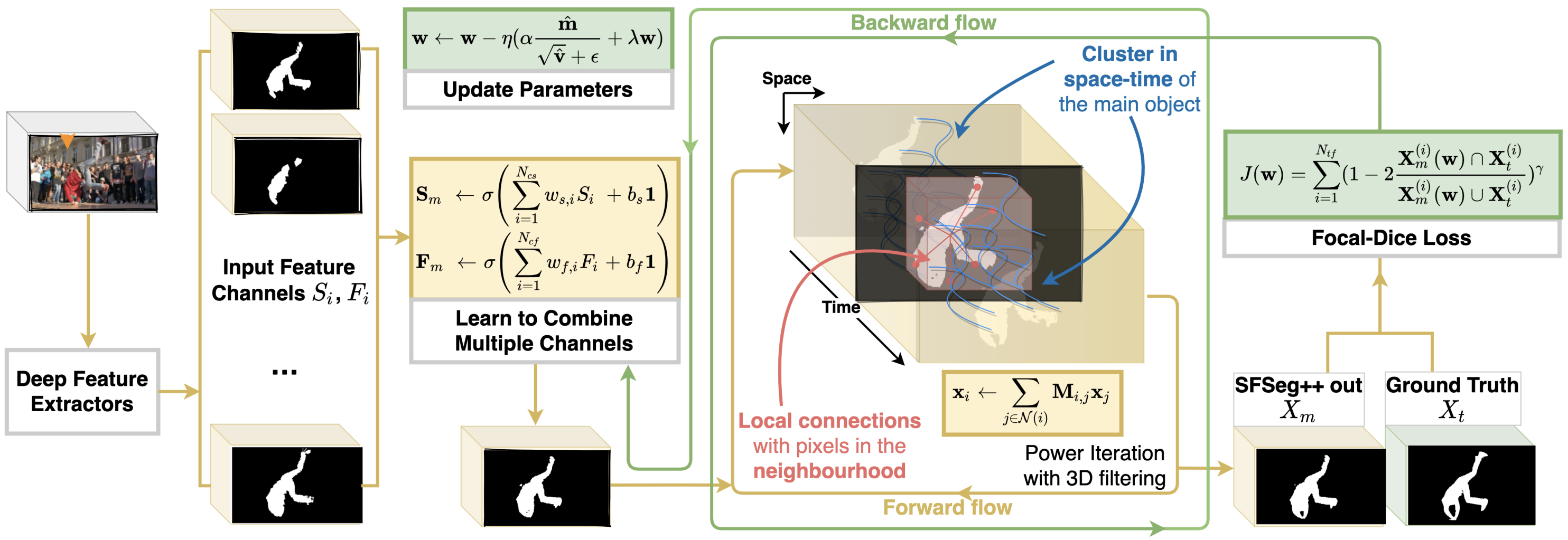
We pose video object segmentation as spectral graph clustering in space and time, with one graph node for each pixel and edges forming local space-time neighborhoods. We claim that the strongest cluster in this video graph represents the salient object. We start by introducing a novel and efficient method based on 3D filtering for approximating the spectral solution, as the principal eigenvector of the graph’s adjacency matrix, without explicitly building the matrix. This key property allows us to have a fast parallel implementation on GPU, orders of magnitude faster than classical approaches for computing the eigenvector. Our motivation for a spectral space-time clustering approach, unique in video semantic segmentation literature, is that such clustering is dedicated to preserving object consistency over time, which we evaluate using our novel segmentation consistency measure. Further on, we show how to efficiently learn the solution over multiple input feature channels. Finally, we extend the formulation of our approach beyond the segmentation task, into the realm of object tracking. In extensive experiments we show significant improvements over top methods, as well as over powerful ensembles that combine them, achieving state-of-the-art on multiple benchmarks, both for tracking and segmentation.
Website Paper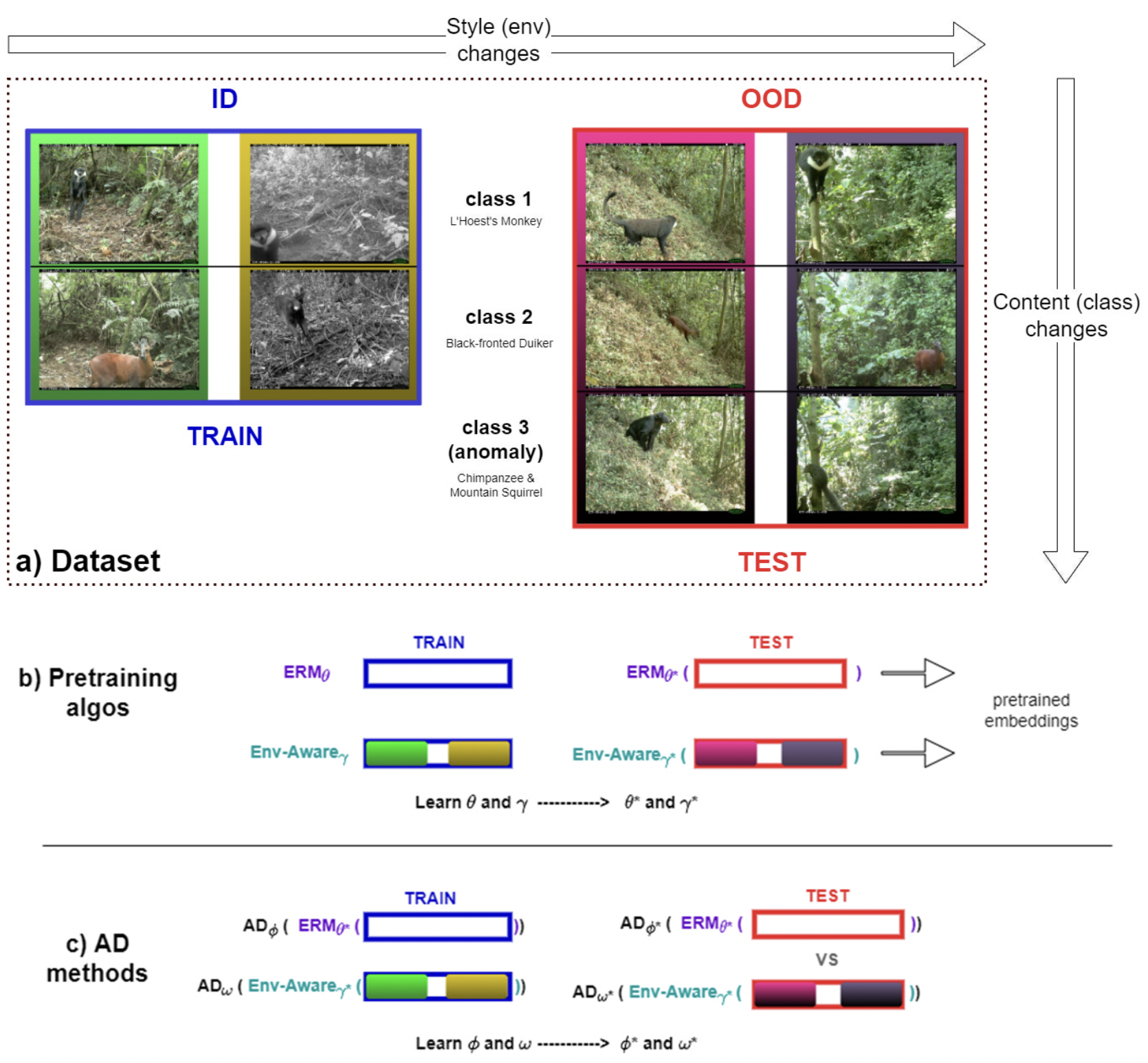
We introduce a formalization and benchmark for the unsupervised anomaly detection task in the distribution-shift scenario. Our work builds upon the iWildCam dataset, and, to the best of our knowledge, we are the first to propose such an approach for visual data. We empirically validate that environment-aware methods perform better in such cases when compared with the basic Empirical Risk Minimization (ERM). We next propose an extension for generating positive samples for contrastive methods that considers the environment labels when training, improving the ERM baseline score by 8.7%.
Paper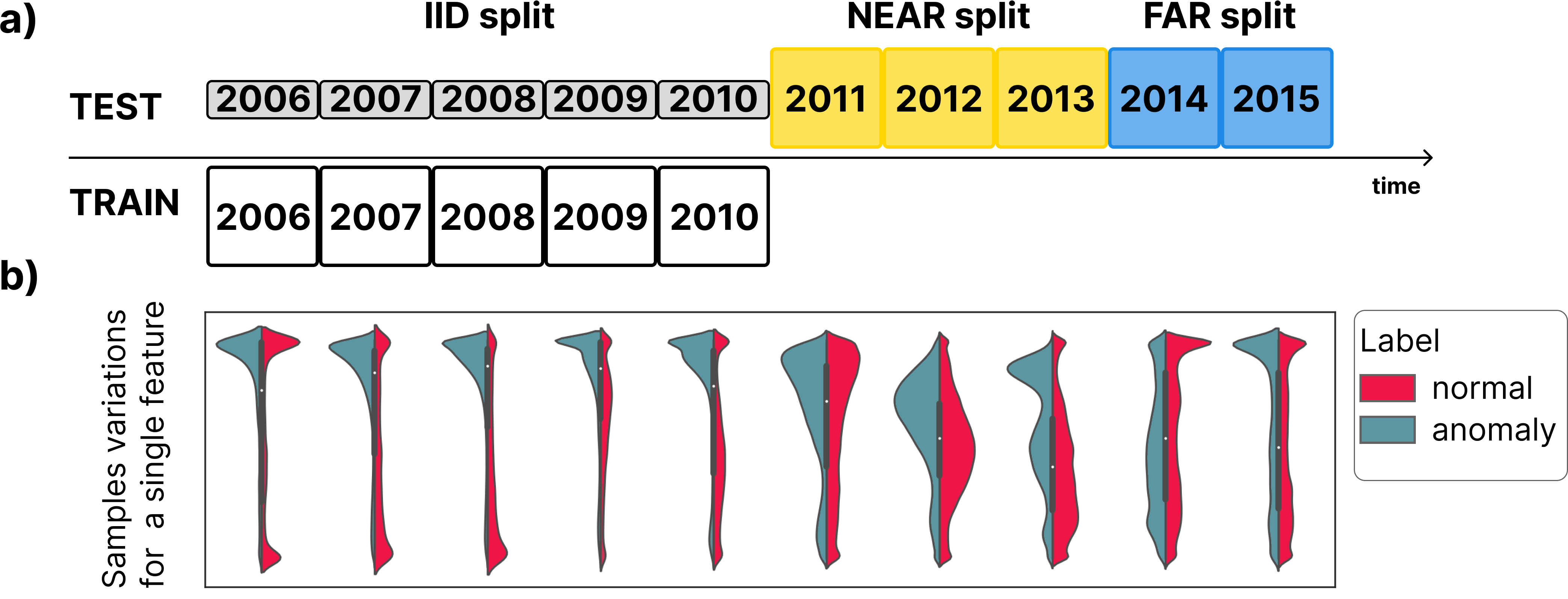
Analyzing the distribution shift of data is a growing research direction in nowadays Machine Learning, leading to emerging new benchmarks that focus on providing a suitable scenario for studying the generalization properties of ML models. The existing benchmarks are focused on supervised learning, and to the best of our knowledge, there is none for unsupervised learning. Therefore, we introduce an unsupervised anomaly detection benchmark with data that shifts over time, meeting the premise of shifting the input distribution: it covers a large time span (10 years), with naturally occurring changes over time (eg users modifying their behavior patterns, and software updates). We first highlight the non-stationary nature of the data, using a basic per-feature analysis, t-SNE, and an Optimal Transport approach for measuring the overall distribution distances between years.
Poster Code Paper
One of the main drivers of the recent advances in authorship verification is the PAN large-scale authorship dataset. Despite generating significant progress in the field, inconsistent performance differences between the closed and open test sets have been reported. To this end, we improve the experimental setup by proposing five new public splits over the PAN dataset, specifically designed to isolate and identify biases related to the text topic and to the author’s writing style. We evaluate several BERT-like baselines on these splits, showing that such models are competitive with authorship verification state-of-the-art methods. Furthermore, using explainable AI, we find that these baselines are biased towards named entities. We show that models trained without the named entities obtain better results and generalize better when tested on DarkReddit, our new dataset for authorship verification.
Paper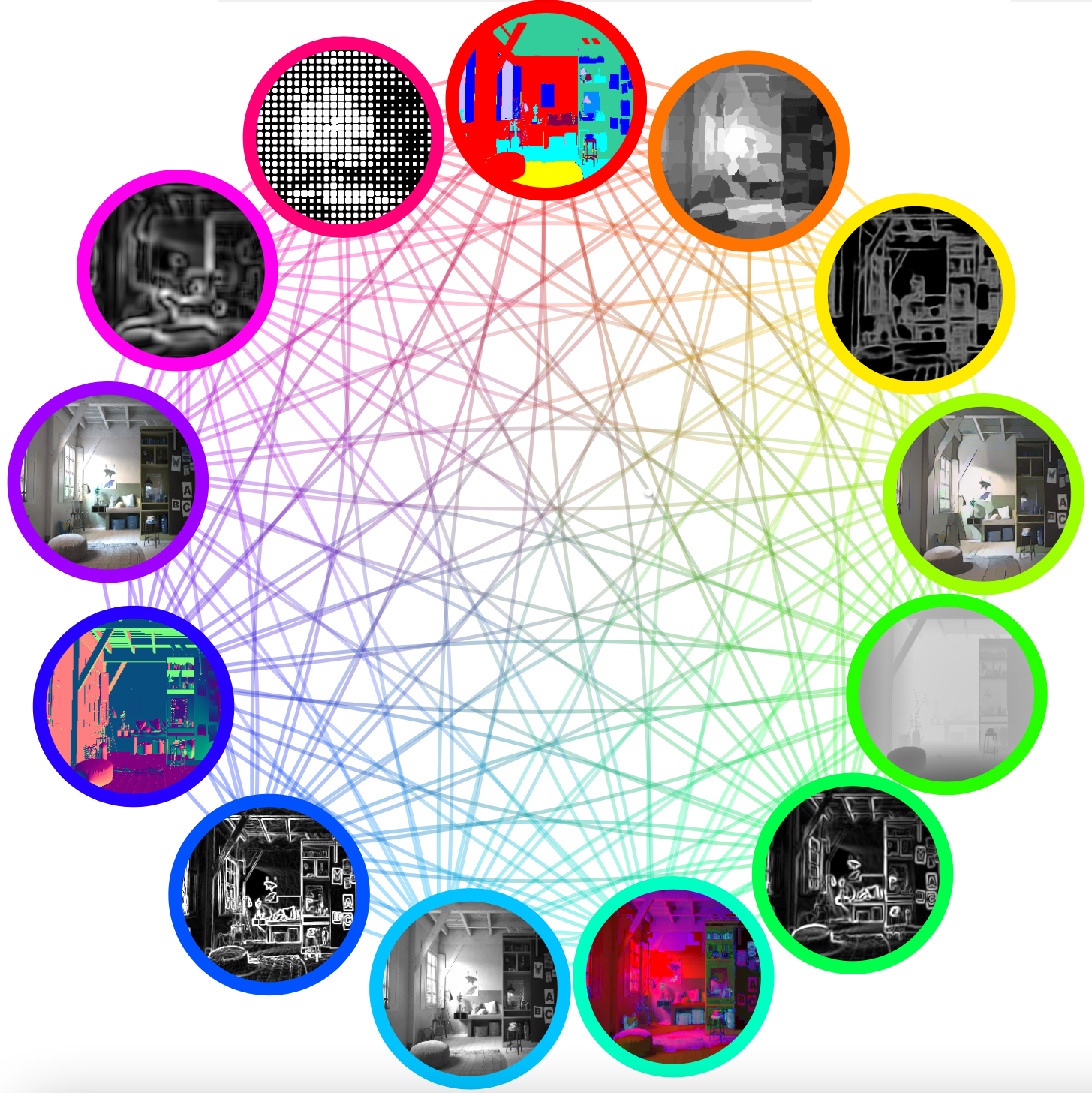
The human ability to synchronize the feedback from all their senses inspired recent works in multi-task and multi-modal learning. While these works rely on expensive supervision, our multi-task graph requires only pseudo-labels from expert models. Every graph node represents a task, and each edge learns between tasks transformations. Once initialized, the graph learns self-supervised, based on a novel consensus shift algorithm that intelligently exploits the agreement between graph pathways to generate new pseudo-labels for the next learning cycle. We demonstrate significant improvement from one unsupervised learning iteration to the next, outperforming related recent methods in extensive multi-task learning experiments on two challenging datasets.
Video Presentation Poster Code Paper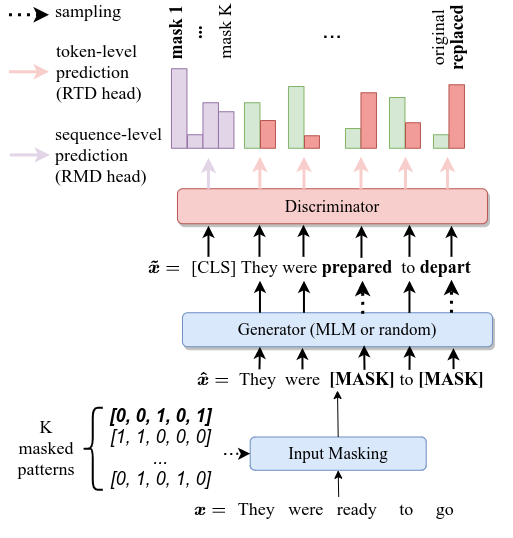
Leveraging deep learning models for Anomaly Detection (AD) has seen widespread use in recent years due to superior performances over traditional methods. Recent deep methods for anomalies in images learn better features of normality in an end-to-end self-supervised setting. These methods train a model to discriminate between different transformations applied to visual data and then use the output to compute an anomaly score. We use this approach for AD in text, by introducing a novel pretext task on text sequences. We learn our DATE model end-to-end, enforcing two independent and complementary self-supervision signals, one at the token-level and one at the sequence-level. Under this new task formulation, we show strong quantitative and qualitative results on the 20Newsgroups and AG News datasets. In the semi-supervised setting, we outperform state-of-the-art results by +13.5% and +6.9%, respectively (AUROC). In the unsupervised configuration, DATE surpasses all other methods even when 10% of its training data is contaminated with outliers (compared with 0% for the others).
Presentation Poster Code Paper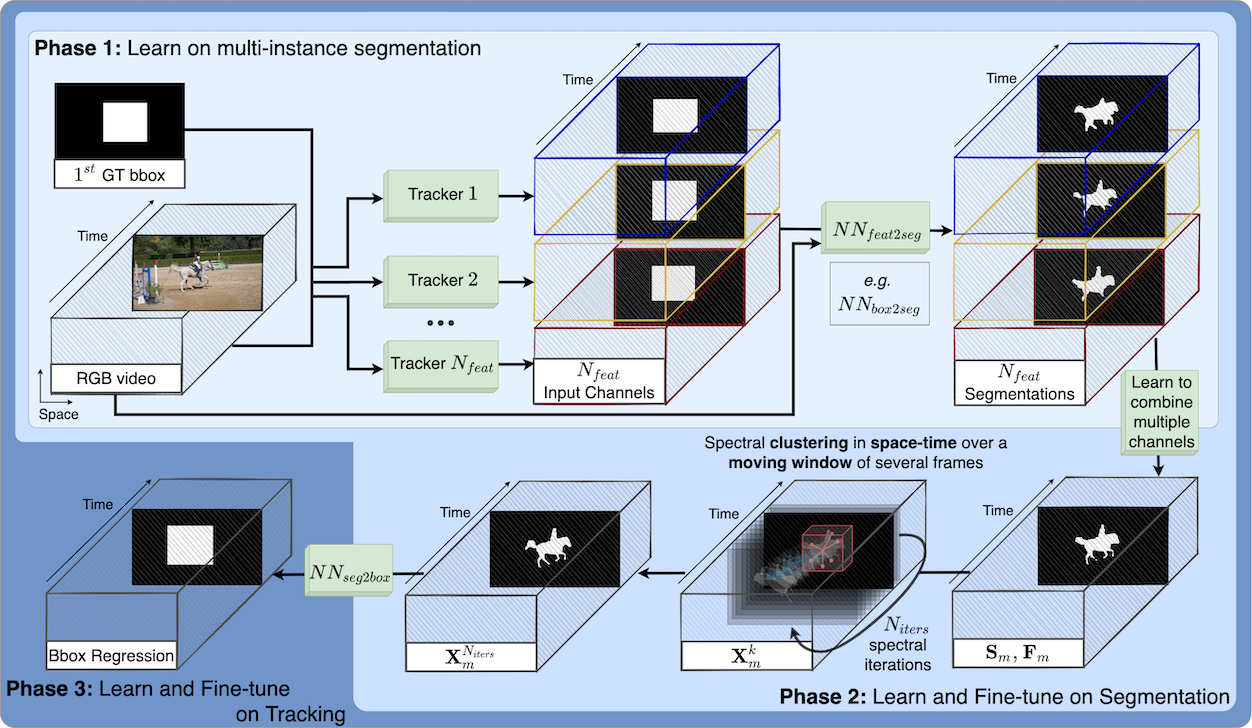
We propose an object tracking method, SFTrack++, that smoothly learns to preserve the tracked object consistency over space and time dimensions by taking a spectral clustering approach over the graph of pixels from the video, using a fast 3D filtering formulation for finding the principal eigenvector of this graph’s adjacency matrix. To better capture complex aspects of the tracked object, we enrich our formulation to multi-channel inputs, which permit different points of view for the same input. We test our method, SFTrack++, on seven tracking benchmarks: VOT2018, LaSOT, TrackingNet, GOT10k, NFS, OTB-100, and UAV123.
Presentation Code Paper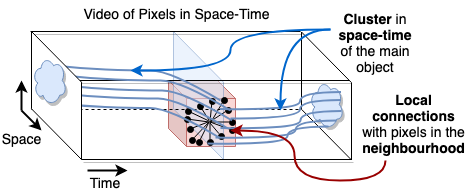
We formulate object segmentation in video as a graph partitioning problem in space and time, in which nodes are pixels and their relations form local neighborhoods. We claim that the strongest cluster in this pixel-level graph represents the salient object segmentation. We compute the main cluster using a novel and fast 3D filtering technique that finds the spectral clustering solution, namely the principal eigenvector of the graph’s adjacency matrix, without building the matrix explicitly - which would be intractable. Our method is based on the power iteration for finding the principal eigenvector of a matrix, which we prove is equivalent to performing a specific set of 3D convolutions in the space-time feature volume.
Video Poster Code Paper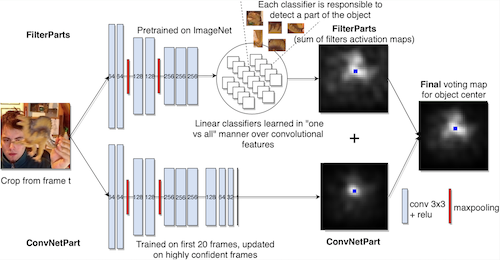
We propose a deep neural network composed of different parts, which functions as a society of tracking parts. They work in conjunction and learn from each other using co-occurrence constraints that ensure robust inference and learning. Our network is composed of two main pathways. One pathway is more conservative, carefully monitoring a large set of simple tracker parts learned as linear filters over deep feature activation maps. We learn these filters simultaneously in an efficient way, with a single closed-form formulation, for which we propose novel theoretical properties. The second pathway is more progressive. It is learned completely online and thus it is able to better model object appearance changes. The larger set of simpler filter parts offers robustness, while the full deep network learned online provides adaptability to change. Thus, our system has the full benefit of two main approaches in tracking.
Presentation Poster PaperWe obtain robustness against background with a tracker model that is composed of many different parts. They are classifiers that respond at different scales and locations. The tracker system functions as a society of parts, each having its own role and level of credibility. Reliable classifiers decide the tracker’s next move, while newcomers are first monitored before gaining the necessary level of reliability to participate in the decision process. Some parts that loose their consistency are rejected, while others that show consistency for a sufficiently long time are promoted to permanent roles. The tracker system, as a whole, could also go through different phases, from the usual, normal functioning to states of weak agreement and even crisis.
PaperCo-organizing (toghether with the Bitdefender team) the event from Bucharest, moderating a panel on Education in AI.
ELIAS aims at establishing Europe as a leader in Artificial Intelligence (AI) research that drives sustainable innovation and economic development.
A large part of our Bitdefender team participating at the event.
Demo course for highschool teachers interested in teaching ML in their 11-12 grade classes, presented together with Emanuela Haller, on classical algorithms vs Machine (Deep) Learning, on healthcare examples.
I defended my PhD at University of Bucharest, with Efficiently Exploiting Space-Time Consensus for Object Segmentation and Tracking in Video thesis, under Marius Leordeanu and Gheorghe Stefanescu supervision. I had outstanding members in the PhD Defense Committee: Tinne Tuytelaars - KU Leuven, João F. Henriques - University of Oxford, Viorica Pătrăucean - Google DeepMind. I am profoundly grateful to you all.
Participating at the event, meeting with the Romanian AI community.
Participating at the event, meeting with the Romanian AI community.
Online help with the Supervised and Unsupervised Tutorials during the virtual summer school.
Help with the organization for one week with 250 students participants and top research speakers.
Received for presenting the poster for Learning a Robust Society of Tracking Parts using Co-occurrence Constraints.
Prepare Machine Learning materials for a HighSchool course, introduced in the national curriculum and keep presentations for various teachers wanting to teach the course to their pupils (all together with an enthusiast team).
Deep Learning Course at University of Bucharest - 4th edition. Every member of the team prepares a lecture or few out of 10 and mentors several students for their final projects. Half of our students were admited at EEML 2022!
Deep Learning Course at University of Bucharest - 3rd edition. Every member of the team prepares a lecture or few out of 10 and mentors several students for their final projects.
Deep Learning Course at University of Bucharest - the second edition. Every member of the team prepares a lecture or few out of 10 and mentors several students for their final projects.
Intro to Deep Learning for Bitdefender Product Managers (2 lectures).
Intro to Deep Learning for Bitdefender Engineers. Every member of the team prepares a lecture or few out of 12 and mentors several colleagues for their projects.
Deep Learning Course at University of Bucharest. Every member of the team prepares a lecture or few out of 10 and mentors several students for their final projects.
